Unlocking the Power of Storage Compute with NoLoad® Transparent Compression

Integrate your CRM with other tools
Lorem ipsum dolor sit amet, consectetur adipiscing elit lobortis arcu enim urna adipiscing praesent velit viverra sit semper lorem eu cursus vel hendrerit elementum morbi curabitur etiam nibh justo, lorem aliquet donec sed sit mi dignissim at ante massa mattis.
- Neque sodales ut etiam sit amet nisl purus non tellus orci ac auctor
- Adipiscing elit ut aliquam purus sit amet viverra suspendisse potenti
- Mauris commodo quis imperdiet massa tincidunt nunc pulvinar
- Adipiscing elit ut aliquam purus sit amet viverra suspendisse potenti
How to connect your integrations to your CRM platform?
Vitae congue eu consequat ac felis placerat vestibulum lectus mauris ultrices cursus sit amet dictum sit amet justo donec enim diam porttitor lacus luctus accumsan tortor posuere praesent tristique magna sit amet purus gravida quis blandit turpis.

Techbit is the next-gen CRM platform designed for modern sales teams
At risus viverra adipiscing at in tellus integer feugiat nisl pretium fusce id velit ut tortor sagittis orci a scelerisque purus semper eget at lectus urna duis convallis. porta nibh venenatis cras sed felis eget neque laoreet suspendisse interdum consectetur libero id faucibus nisl donec pretium vulputate sapien nec sagittis aliquam nunc lobortis mattis aliquam faucibus purus in.
- Neque sodales ut etiam sit amet nisl purus non tellus orci ac auctor
- Adipiscing elit ut aliquam purus sit amet viverra suspendisse potenti venenatis
- Mauris commodo quis imperdiet massa at in tincidunt nunc pulvinar
- Adipiscing elit ut aliquam purus sit amet viverra suspendisse potenti consectetur
Why using the right CRM can make your team close more sales?
Nisi quis eleifend quam adipiscing vitae aliquet bibendum enim facilisis gravida neque. Velit euismod in pellentesque massa placerat volutpat lacus laoreet non curabitur gravida odio aenean sed adipiscing diam donec adipiscing tristique risus. amet est placerat.
“Nisi quis eleifend quam adipiscing vitae aliquet bibendum enim facilisis gravida neque velit euismod in pellentesque massa placerat.”
What other features would you like to see in our product?
Eget lorem dolor sed viverra ipsum nunc aliquet bibendum felis donec et odio pellentesque diam volutpat commodo sed egestas aliquam sem fringilla ut morbi tincidunt augue interdum velit euismod eu tincidunt tortor aliquam nulla facilisi aenean sed adipiscing diam donec adipiscing ut lectus arcu bibendum at varius vel pharetra nibh venenatis cras sed felis eget.
Unlocking the Power of Storage Compute with NoLoad® Transparent Compression
Today’s computational workloads are larger, more complex, and more diverse than ever before. As data continues to grow at an unprecedented rate, traditional storage and compute architectures are struggling to keep up, creating bottlenecks that slow innovation and drive-up costs. The explosion of applications such as high-performance computing (HPC), artificial intelligence (AI), machine learning (ML), data analytics, and other specialized tasks is driving the exponential growth of data.
To address these challenges, acceleration technologies like Eideticom’s NoLoad® provide high-performance compression and decompression, freeing up valuable CPU resources while improving efficiency. The NoLoad Transparent Compression (TC) solution provides a performant and future-proof platform to augment and replace legacy solutions such as Intel Quick Assist Technology (QAT) compression. In this blog we provide an overview of Transparent Compression, dive into several use cases and provide benchmarks outlining the performance advantages of the NoLoad platform.
Transparent Compression
As data volumes continue to grow, new capabilities are needed to efficiently move, manage, and protect information. Critical functions- such as virtualization, data protection, data security (encryption), and compression - are essential to optimize performance and reduce costs; however, these capabilities involve substantial infrastructure resources consuming significant CPU cycles and impacting overall system efficiency.
In the datacenter space, FPGAs offer the low latency offloading necessary to accelerate functions, such as data analytics, artificial intelligence, smart networking, hyper-converged storage, and other functions. FPGAs support in-line, look-aside, and multifunction processing modes to offload CPU workloads by reducing complex bottlenecks (Figure 1).

Transparent inline compression (TC) is a technique that processes data as it is written to or read from storage or memory, automatically compressing data on write and decompressing it on read, without requiring separate actions from the host system. Utilizing NoLoad TC provides necessary high-performance compression while improving overall system efficiency without requiring any application changes.
NoLoad Solution and QAT
Eideticom’s transparent compression solution accelerates and secures a wide variety of use cases; however, some specific applications include database users like FinTech, HPC and Enterprise datacenter customers who need large bandwidth in hardware with low latency. Tasks can be parallelized to meet any bandwidth needs and decompression can be pipelined with other NoLoad IP such as compression, erasure coding and deduplication. The NoLoad software stack allows transparent access to NoLoad compression and decompression services in the filesystem, kernel space, or user space. The NoLoad software stack also allows for interoperable and transparent access to the Intel QuickAssist (QAT) cores available on 4th Generation Xeon CPUs. The NoLoad software stack allows users to access NoLoad FPGA-based and QAT-based compression without modifying their applications. Combining the computational resources of NoLoad to perform decompression and Intel QAT to perform compression, the overall throughput of a system is drastically improved.
Intel QAT has long been a go-to solution for accelerating data center workloads such as compression/decompression, but its future remains uncertain. With no clear public roadmap for upcoming generations, businesses relying on QAT face increasing risks of stagnation, supply constraints, and long-term support challenges. In combination with Eideticom’s easily deployed transparent compression software stack, NoLoad FPGA acceleration provides a high-performance Intel QAT alternative offering seamless integration at the application level. Organization scan adopt NoLoad as an Intel QAT alternative while also leveraging Eideticom’s transparent compression software stack to integrate both solutions, ensuring flexibility and a smooth transition without disrupting existing workloads.
Benchmark Testing Storage Use-Cases
Benchmarks were performed which compared typical high-end FinTech and HPC storage tasks performed on three different computational environments. These real-world examples featured data storage for single write multiple read software applications. In this benchmark, packets are transparently compressed as data is written to the storage array and decompressed as data is read from the storage array using Eideticom’s NoLoad® software stack.

The second scenario of the benchmark augmented the solution to use the QAT on the 4th Gen Intel® Xeon® Scalable processors to perform both compression and decompression tasks as data was being written to and read from the disks (Figure 3).Transparent QAT compression/decompression was provided by Eideticom’s NoLoad® software stack.

The third scenario of the benchmark augmented the CPU with an FPGA-based accelerator card all tied together with Eideticom’s NoLoad transparent compression software stack. The hardware for the second scenario (Figure 4)used the previously described single socket 4th Gen Xeon server and an FPGA-based accelerator card. The QAT on the 4th Gen Intel® Xeon® Scalable processors was used to provide compression and one Agilex 7 AGI023 card, loaded with Eideticom’s NoLoad, was used for decompression.

The fourth scenario of the benchmark represents the use of Eideticom’s NoLoad transparent compression software stack to perform both compression and decompression operations. Results were compiled using the same Agilex 7 AGI023 card loaded with Eideticom’s NoLoad.

Benchmark Results
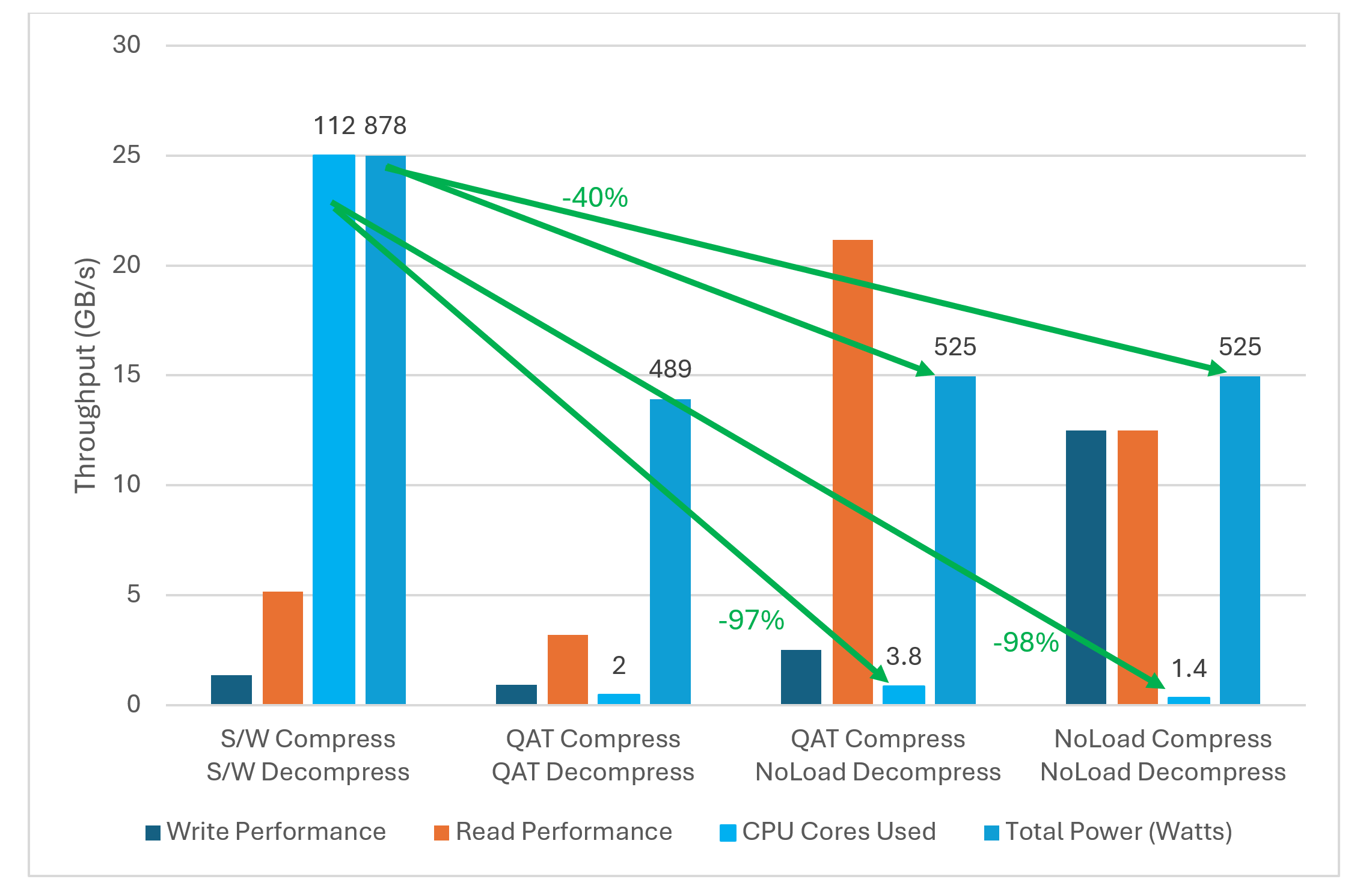
Analyzing the measurement results (Figure 6) for software (S/W) compression/decompression compared to QAT compression/decompression, significant CPU cores were freed up for other processing and total power was reduced for a small reduction in read and write performance. Comparing S/W compression to QAT compression and FPGA-based decompression, it is clear the FPGA-based accelerator scenario resulted in superior read and write performance and used fewer number of CPU cores and lower total system power. The total power for the FPGA scenario is the total power of the system, including CPU cores, NVMe storage, and the FPGA card. The CPU cores freed up by the FPGA off-load + NoLoad solution are now available for use on other tasks/workloads.
- 98% reduction in CPU cores used (lower is better)
- 40% reduction in power used (lower is better)
Summary
Today’s computational workloads are larger, more complex, and more diverse than ever before. By combining the newest Intel products with innovative solutions from partners, such as Eideticom, customers can achieve significant TCO savings for their workloads. FinTech, HPC, content delivery, and AI are all verticals where it is advantageous to offload algorithmically intensive and latency sensitive functions to accelerator cards, freeing up host CPU cores to perform other money-earning tasks.
As a direct Intel QAT replacement, NoLoad transparent compression/decompression is a tunable solution that delivers superior performance, efficiency, and scalability. Unlike QAT, which is limited by fixed hardware configurations and firmware constraints, NoLoad leverages FPGA-based acceleration to optimize performance based on workload demands. Benchmarking shows that NoLoad achieves higher throughput and better CPU efficiency for both compression and decompression. Organizations can deploy NoLoad as a full QAT replacement or integrate it alongside existing QAT deployments using Eideticom’s software stack for a seamless transition. With higher throughput, lower latency, and broader algorithm support, NoLoad provides a future-proof approach to accelerating compression and decompression in modern data centers.


